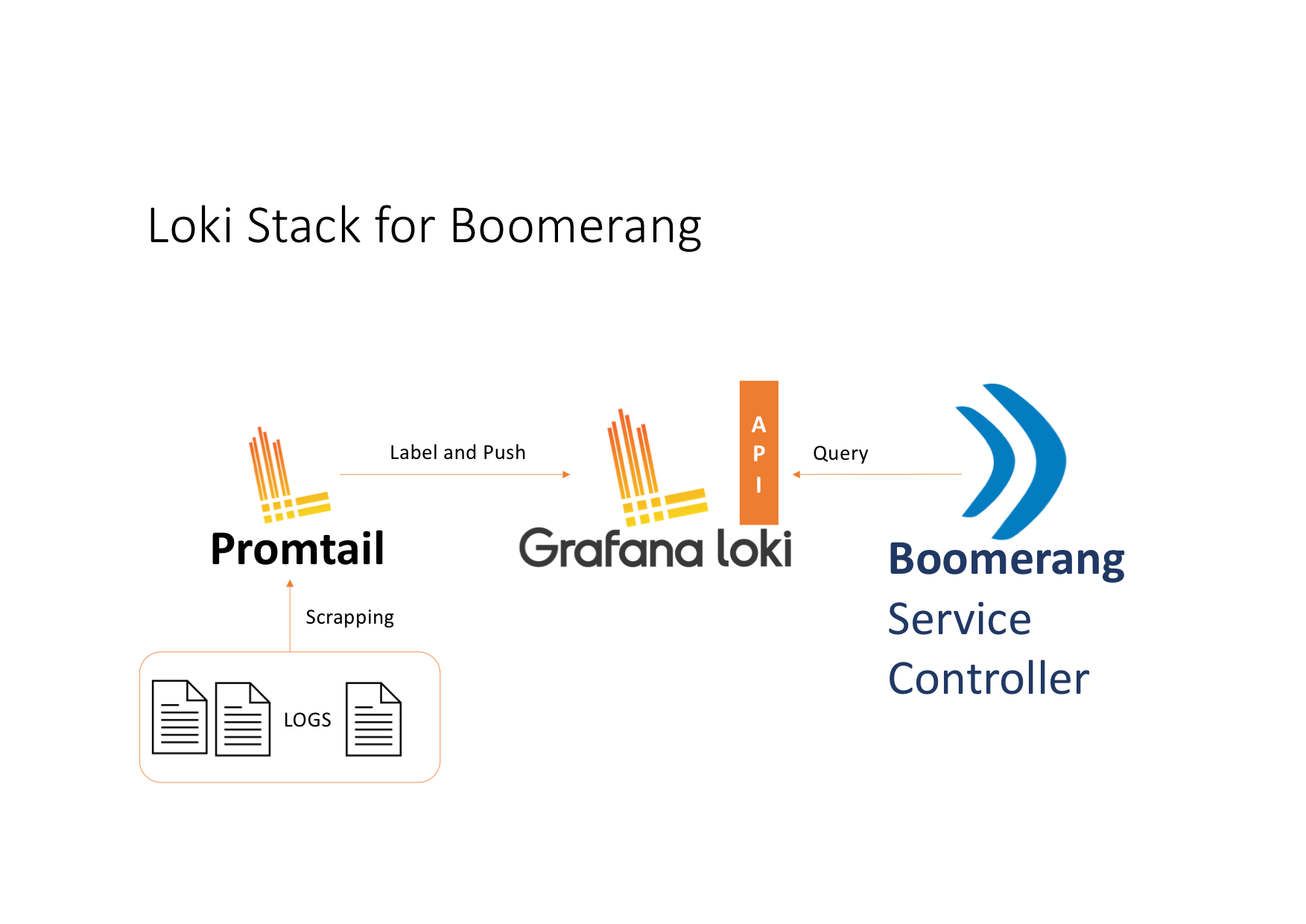
Grafana® LokiTM is a solution that covers the entire logging stack following the success story of Prometheus and how this technology optimizes the metrics, transmission, and indexing process. Compared to ELK, Loki uses a lightweight indexing mechanism which groups log entries into streams and tags them with a particular set of labels and values.
The log entries are stored as plaintext (in raw format) and are further identified by the subset of labels corresponding to their origin (for example, env=production, app=frontend). Particularly for Kubernetes®, source tags can often correspond to the labelling convention used within the definition of the pods.
The indexing mechanism becomes effective when the logs have to be consumed aggressively and they have to be available as quick as possible. Loki does not iterate through the log content in order to generate the index map, therefore, no further content analyses will be performed. Scenarios similar to the following: I need to capture all the HTTP 50* errors from my front-end web servers, occurred during a POST form submission may better fit solutions like ELK where the platform establish indexing based on the content analysis.
[FRONTEND]
|___[HTTP/GET(query_range)]____
|
_________________[HTTP/POST]____________ 3100/tcp[LOKI]
| | |
[PROMTAIL i1] [PROMTAIL i2] .... [PROMTAIL iN]
__________ __________ __________
[NODE 1] [NODE 2] [NODE N]
| Chart | Version |
|---|---|
| grafana/loki | 2.5.0 |
| grafana/promtail | 3.5.0 |
Step 0
Create a dedicated namespace for the Loki stack.
kubectl create ns bmrg-loki
Step 1
Add the official Grafana Labs repository to the helm repo list.
helm repo add grafana https://grafana.github.io/helm-charts
Step 2
Generate the values files corresponding to the charts versions listed in prerequisites.
helm inspect values --version 2.5.0 grafana/loki > loki-values-v2.5.0.deploy.yaml
helm inspect values grafana/promtail --version 3.5.0 > promtail-values-v3.5.0.deploy.yaml
Aspects to be considered:
config.lokiAddress: http://bmrg-loki:3100/loki/api/v1/push
Use the scrapeConfig defined in Scrape Configurations.
Configure the pipeline based on the containers engine in use as defined in Pipeline Stages.
Remember: When using an Openshift the Pod Security Policies admission controller has been replaced by the Security Context Constraints admission controller. In this regard, extra steps must be performed:
Escalate Promtail privileges.
containerSecurityContext:
privileged: true
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
allowPrivilegeEscalation: true
Create a service account and link the privileged and hostmount-anyuid SCC to it.
Values file:
serviceAccount:
# -- Specifies whether a ServiceAccount should be created
create: true
# -- The name of the ServiceAccount to use.
# If not set and `create` is true, a name is generated using the fullname template
name: bmrg-promtail-sa
# -- Image pull secrets for the service account
imagePullSecrets: []
# -- Annotations for the service account
annotations: {}
K8S objects file (use oc apply -f <file name>):
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
creationTimestamp: null
name: promtail-role
rules:
- apiGroups:
- security.openshift.io
resourceNames:
- privileged
- hostmount-anyuid
resources:
- securitycontextconstraints
verbs:
- use
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
creationTimestamp: null
name: promtail-priv
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: promtail-role
subjects:
- kind: ServiceAccount
name: bmrg-promtail-sa
namespace: bmrg-loki
In the Loki values file, disable the security context, as OpenShift® has it's own mechanism to manage it.
securityContext:
fsGroup: null
runAsGroup: null
runAsNonRoot: true
runAsUser: null
serviceAccount:
create: false
name:
annotations: {}
Step 3
Install Loki (ingestion service) and wait for the service to run:
helm upgrade --install --debug --namespace bmrg-loki -f loki-values-v2.5.0.deploy.yaml --version 3.5.0 bmrg-promtail grafana/promtail
Step 4
Install Promtail daemonset (agent):
helm upgrade --install --debug --namespace bmrg-loki -f promtail-values-v3.5.0.deploy.yaml --version 3.5.0 bmrg-promtail grafana/promtail
Remarks:
Due to the tight scraping configuration, adapted to capture logs only from Flow & CICD jobs, some Promtail agents may be in an error state failing the readiness probe (0/1 READY). If the Promtail pod logs display a message similar to the one below, the error can be disregarded.
level=warn ts=2021-03-13T16:40:59.636745016Z caller=logging.go:62 msg="GET /ready (500) 56.509µs Response: \"Not ready: Unable to find any logs to tail. Please verify permissions, volumes, scrape_config, etc.\\n\" ws: false; Accept-Encoding: gzip; Connection: close; User-Agent: kube-probe/1.13; "
This particular error says that no active pod, running on the target node, matches the scrape configuration. In other words, no Flow or CICD job has been scheduled on the target node.
config:
auth_enabled: false
[...]
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
schema_config:
[...]
server:
http_listen_port: 3100
storage_config:
[...]
chunk_store_config:
max_look_back_period: 168h
table_manager:
retention_deletes_enabled: true
retention_period: 168h
[...]
Depending on the container engine used by the Kubernetes flavor, the logs format may differ and therefore, in order to retrieve relevant information, the pipeline stages must be configured according to this format.
config:
[...]
snippets:
pipelineStages:
- json:
expressions:
output: log
- output:
source: output
config:
[...]
snippets:
pipelineStages:
- regex:
expression: "^(?s)(?P<time>\\S+?) (?P<stream>stdout|stderr) (?P<flags>\\S+?) (?P<content>.*)$"
- output:
source: content
- replace:
expression: "()\\z"
replace: " \n"
scrapeConfigs: |
- job_name: bmrg-job
kubernetes_sd_configs:
- role: pod
pipeline_stages:
{{- toYaml .Values.config.snippets.pipelineStages | nindent 4 }}
relabel_configs:
- source_labels:
- __meta_kubernetes_pod_label_boomerang_io_Workflow_id
target_label: bmrg_Workflow
- source_labels:
- __meta_kubernetes_pod_label_boomerang_io_activity_id
target_label: bmrg_activity
- source_labels:
- __meta_kubernetes_pod_label_boomerang_io_Task_id
target_label: bmrg_Task
- source_labels:
- __meta_kubernetes_pod_label_boomerang_io_Workflow_activity_id
target_label: bmrg_Workflow_activity
- source_labels:
- __meta_kubernetes_pod_label_boomerang_io_Task_activity_id
target_label: bmrg_Task_activity
- source_labels:
- __meta_kubernetes_pod_label_boomerang_io_tier
target_label: __bmrg_tier__
- source_labels:
- __meta_kubernetes_pod_label_boomerang_io_product
target_label: bmrg_product
- source_labels:
- __meta_kubernetes_pod_container_name
target_label: bmrg_container
- source_labels:
- __meta_kubernetes_pod_node_name
target_label: __host__
- action: drop
regex: ""
source_labels:
- bmrg_Workflow_activity
- action: drop
regex: ""
source_labels:
- bmrg_Task_activity
- action: drop
regex: ""
source_labels:
- bmrg_Workflow
- action: drop
regex: ""
source_labels:
- bmrg_Task
- action: keep
regex: Task-cntr|worker-cntr|step-[a-zA-Z0-9][a-zA-Z0-9_-]*
source_labels:
- bmrg_container
- action: keep
regex: bmrg-flow|bmrg-cicd-flow
source_labels:
- bmrg_product
{{- toYaml .Values.config.snippets.common | nindent 2 }}
Log file discovery:
config:
[...]
snippets:
common:
- replacement: /var/log/pods/*$1/*.log
separator: /
source_labels:
- __meta_kubernetes_pod_uid
- __meta_kubernetes_pod_container_name
target_label: __path__
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/Task-worker
operator: Exists
tolerations:
- key: dedicated
operator: Equal
effect: NoSchedule
value: "bmrg-worker"
In case the access to Grafana UI needs to be secured and allow access only to certain users, it can be achieved by following these steps.
spec:
containers:
- image: "grafana/grafana:8.0.0"
...
- name: grafana-ngx-cnt
image: "nginx:1.21.0-alpine"
ports:
- containerPort: 80
name: grfn-ngx-port
protocol: TCP
volumeMounts:
- name: grafana-ngx-cfg
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
- name: grafana-ngx-cfg
mountPath: /etc/nginx/jwt.js
subPath: jwt.js
X-WEBAUTH-USER header with the authenticated user's email.data:
nginx.conf: |
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
load_module /usr/lib/nginx/modules/ngx_http_js_module.so;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
js_import jwt.js;
js_set $user_email jwt.get_user_email;
upstream grafana_backend {
server localhost:3000;
}
server {
listen 80;
listen [::]:80;
server_name localhost;
location /ess/grafana {
proxy_set_header X-WEBAUTH-USER $user_email;
proxy_set_header Authorization "";
proxy_pass http://grafana_backend;
}
}
}
jwt.js: |
function extract_jwt(data) {
var parts = data.split('.').slice(0,2)
.map(v=>Buffer.from(v, 'base64url').toString())
.map(JSON.parse);
return { headers:parts[0], payload: parts[1] };
}
function get_user_email(request) {
var user_email = "";
if(request.headersIn.Authorization) {
var jwt = extract_jwt(request.headersIn.Authorization.slice(7));
user_email = jwt.payload.email || jwt.payload.emailAddress;
}
return user_email;
}
export default {get_user_email}
js_import jwt.js;
js_set $user_email jwt.get_user_email;
data:
grafana.ini: |
[users]
allow_sign_up = false
auto_assign_org = true
auto_assign_org_role = Editor
[auth.proxy]
enabled = true
header_name = X-WEBAUTH-USER
header_property = email
auto_sign_up = true
[server]
serve_from_sub_path = true
root_url = /ess/grafanakind: Service
metadata:
name: grafana-service
spec:
selector:
app: grafana
ports:
- name: grfn-port-svc
port: 80
targetPort: grfn-ngx-port
protocol: TCP